1) Darwin and Wallace's theory of evolution by natural selection was revolutionary because it _____.
A) was the first theory to refute the ideas of special creation
B) proved that individuals acclimated to their environment over time
C) dismissed the idea that species are constant and emphasized the importance of variation and change in populations
D) was the first time a biologist had proposed that species changed through time
C) dismissed the idea that species are constant and emphasized the importance of variation and change in populations
2) Catastrophism was Cuvier's attempt to explain the existence of _____.
A) evolution
B) the fossil record
C) uniformitarianism
D) the origin of new species
B) the fossil record
3) With what other idea of his time was Cuvier's theory of catastrophism most in conflict?
A) the scala naturae
B) the fixity of species
C) island biogeography
D) uniformitarianism
D) uniformitarianism
4) Prior to the work of Lyell and Darwin, the prevailing belief was that Earth is _____.
A) a few thousand years old, and populations are unchanging
B) a few thousand years old, and populations gradually change
C) millions of years old, and populations rapidly change
D) millions of years old, and populations are unchanging
A) a few thousand years old, and populations are unchanging
5) During a study session about evolution, one of your fellow students remarks, "The giraffe stretched its neck while reaching for higher leaves; its offspring inherited longer necks as a result." Which statement is most likely to be helpful in correcting this student's misconception?
A) Characteristics acquired during an organism's life are generally not passed on through genes.
B) Spontaneous mutations can result in the appearance of new traits.
C) Only favorable adaptations have survival value.
D) Disuse of an organ may lead to its eventual disappearance.
A) Characteristics acquired during an organism's life are generally not passed on through genes.
6) When Cuvier considered the fossils found in the vicinity of Paris, he concluded that the extinction of species _____.
A) occurs, but that there is no evolution
B) and the evolution of species both occur
C) and the evolution of species do not occur
D) does not occur, but evolution does occur
A) occurs, but that there is no evolution
7) In the mid-1900s, the Soviet geneticist Lysenko believed that his winter wheat plants, exposed to increasingly colder temperatures, would eventually give rise to more cold-tolerant winter wheat. Lysenko's attempts in this regard were most in agreement with the ideas of _____.
A) Cuvier
B) Lamarck
C) Darwin
D) Lyell
B) Lamarck

8) If x indicates the location of fossils of two closely related species, then fossils of their most-recent common ancestor are most likely to occur in which stratum?
A) A
B) B
C) C
D) D
C) C

9) If x indicates the fossils of two closely related species, neither of which is extinct, then their remains may be found in how many of these strata?
A) one stratum
B) two strata
C) three strata
D) four strata
B) two strata
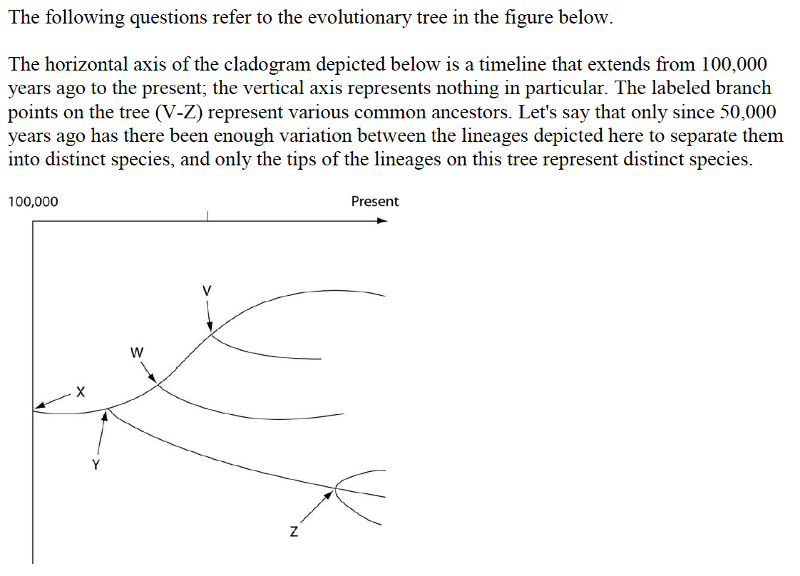
10) Which pair of scientists below would probably have agreed with the process that is depicted by this tree?
A) Cuvier and Lamarck
B) Lamarck and Wallace
C) Aristotle and Lyell
D) Wallace and Linnaeus
B) Lamarck and Wallace
11) The cow Bos primigenius (which is bred for meat and milk) has a smaller brain and larger eyes than closely related wild species of ungulates. These traits most likely arose by _____.
A) natural selection, because these traits evolved in the population over time
B) natural selection, because these traits were not consciously selected by humans
C) artificial selection, because changes in these traits co-occurred with human selection for high milk output and high muscle content
D) artificial selection, because these animals differ from their close relatives and common ancestor
C) artificial selection, because changes in these traits co-occurred with human selection for high milk output and high muscle content
12) Starting from the wild mustard Brassica oleracea, breeders have created the strains known as Brussels sprouts, broccoli, kale, and cabbage. Therefore, which of the following statements is correct?
A) In this wild mustard, there is enough heritable variation to permit these different varieties.
B) Heritable variation is low in wild mustard—otherwise this wild strain would have different characteristics.
C) Natural selection is rare in wild populations of wild mustard.
D) In wild mustard, most of the variation is due to differences in soil or other aspects of the environment.
A) In this wild mustard, there is enough heritable variation to permit these different varieties.
13) Which of the following scientists argued that variation among individuals allows evolution to occur?
A) Aristotle
B) Lamarck
C) Linnaeus
D) Wallace
D) Wallace
14) Which of these conditions are always true of populations evolving due to natural selection?
Condition 1: The population must vary in traits that are heritable.
Condition 2: Some heritable traits must increase reproductive success.
Condition 3: Individuals pass on most traits that they acquire during their lifetime.
A) Condition 1 only
B) Condition 2 only
C) Conditions 1 and 2
D) Conditions 2 and 3
C) Conditions 1 and 2
15) A farmer uses triazine herbicide to control pigweed in his field. For the first few years, the triazine works well and almost all the pigweed dies; but after several years, the farmer sees more and more pigweed. Which of these explanations best explains what happened?
A) The herbicide company lost its triazine formula and started selling poor-quality triazine.
B) Natural selection caused the pigweed to mutate, creating a new triazine-resistant species.
C) Triazine-resistant pigweed has less-efficient photosynthesis metabolism.
D) Triazine-resistant weeds were more likely to survive and reproduce.
D) Triazine-resistant weeds were more likely to survive and reproduce.
16) After the drought of 1977, researchers on the island of Daphne Major hypothesized that medium ground finches that had large, deep beaks, survived better than those with smaller beaks because they could more easily crack and eat the tough Tribulus cistoides fruits. If this hypothesis is correct, what would you expect to observe if a population of these medium ground finches colonizes a nearby island where Tribulus cistoides is the most abundant food for the next 1000 years? Assume that (1) even the survivors of the 1977 drought sometimes had difficulty cracking the tough T. cistoides fruits and would eat other seeds when offered a choice; and (2) food availability is the primary limit on finch fitness on this new island.
A) evolution of yet larger, deeper beaks over time
B) evolution of smaller, pointier beaks over time
C) random fluctuations in beak size and shape
D) no change in beak size and shape
A) evolution of yet larger, deeper beaks over time
17) After the drought of 1977, researchers hypothesized that on the Galápagos island Daphne Major, medium ground finches with large, deep beaks survived better than those with smaller beaks because they could more easily crack and eat the tough Tribulus cistoides fruits. A tourist company sets up reliable feeding stations with a variety of bird seeds (different types and sizes) so that tourists can get a better look at the finches. Which of these events is now most likely to occur to finch beaks on this island?
A) evolution of yet larger, deeper beaks over time, until all birds have relatively large, deep beaks
B) evolution of smaller, pointier beaks over time, until all birds have relatively small, pointy beaks
C) increased variation in beak size and shape over time
D) no change in beak size and shape over time
C) increased variation in beak size and shape over time
18) Claytonia virginica is a woodland spring herb with flowers that vary from white to pale pink to bright pink. Slugs prefer to eat pink-flowering over white-flowering plants (due to chemical differences between the two), and plants experiencing severe herbivory are more likely to die. The bees that pollinate this plant also prefer pink to white flowers, so that Claytonia with pink flowers have greater relative fruit set than Claytonia with white flowers. A researcher observes that the percentage of different flower colors remains stable in the study population from year to year. Given no other information, if the researcher removes all slugs from the study population, what do you expect to happen to the distribution of flower colors in the population over time?
A) The percentage of pink flowers should increase over time.
B) The percentage of white flowers should increase over time.
C) The distribution of flower colors should not change.
D) The distribution of flower colors should randomly fluctuate over time.
A) The percentage of pink flowers should increase over time.
19) Parasitic species tend to have simple morphologies. Which of the following statements best explains this observation?
A) Parasites are lower organisms, and this is why they have simple morphologies.
B) Parasites do not live long enough to inherit acquired characteristics.
C) Simple morphologies convey some advantage in most parasites.
D) Parasites have not yet had time to progress, because they are young evolutionarily.
C) Simple morphologies convey some advantage in most parasites.
20) Darwin and Wallace were the first to propose _____.
A) that evolution occurs
B) a mechanism for how evolution occurs
C) that Earth is older than a few thousand years
D) natural selection as the mechanism of evolution
D) natural selection as the mechanism of evolution
21) A population of organisms will not evolve if _____.
A) all individual variation is due only to environmental factors
B) the environment is changing at a relatively slow rate
C) the population size is large
D) the population lives in a habitat without competing species present
A) all individual variation is due only to environmental factors
22) Which of the following represents an idea that Darwin learned from the writings of Thomas Malthus?
A) Technological innovation in agricultural practices will permit exponential growth of the human population into the foreseeable future.
B) Populations tend to increase at a faster rate than their food supply normally allows.
C) Earth changed over the years through a series of catastrophic upheavals.
D) The environment is responsible for natural selection.
B) Populations tend to increase at a faster rate than their food supply normally allows.
23) Given a population that contains genetic variation, what is the correct sequence of the following events under the influence of natural selection?
1. Well-adapted individuals leave more offspring than do poorly adapted individuals.
2. A change occurs in the environment.
3. Genetic frequencies within the population change.
4. Poorly adapted individuals have decreased survivorship.
A) 2 → 4 → 1 → 3
B) 4 → 2 → 1 → 3
C) 4 → 2 → 3 → 1
D) 2 → 4 → 3 → 1
A) 2 → 4 → 1 → 3
24) A biologist studied a population of squirrels for fifteen years. During that time, the population was never fewer than thirty squirrels and never more than forty-five. Her data showed that over half of the squirrels born did not survive to reproduce, because of both competition for food and predation. In a single generation, 90% of the squirrels that were born lived to reproduce, and the population increased to eighty. Which inference(s) about this most recent surge in the population size might be true?
A) The amount of available food may have increased.
B) The parental generation of squirrels developed better eyesight due to improved diet; the subsequent squirrel generation inherited better eyesight.
C) The number of predators that prey upon squirrels may have decreased.
D) The amount of available food may have increased and/or the predators that prey upon squirrels may have decreased.
D) The amount of available food may have increased and/or the predators that prey upon squirrels may have decreased.
25) Which of the following must exist in a population before natural selection can act upon that population?
A) genetic variation among individuals
B) variation among individuals caused by environmental factors
C) sexual reproduction
D) the population has predators
A) genetic variation among individuals
26) Which of Darwin's ideas had the strongest connection to his reading of Malthus's essay on human population growth?
A) descent with modification
B) variation among individuals in a population
C) struggle for existence
D) that the ancestors of the Galápagos finches had come from the South American mainland
C) struggle for existence
27) If Darwin had been aware of genes and their typical mode of transmission to subsequent generations, with which statement would he most likely have been in agreement?
A) If natural selection can change gene frequency in a population over generations, given enough time and genetic diversity, then natural selection can cause sufficient genetic change to produce new species from old ones.
B) If an organism's somatic cell genes change during its lifetime, making it more fit, then it will be able to pass these genes on to its offspring.
C) If an organism acquires new genes by engulfing, or being infected by, another organism, then a new genetic species will result.
D) A single mutation in a single gene in a single gamete, if inherited by future generations, will produce a new species.
A) If natural selection can change gene frequency in a population over generations, given enough time and genetic diversity, then natural selection can cause sufficient genetic change to produce new species from old ones.
28) The role that humans play in artificial selection is to _____.
A) determine who lives and who dies
B) create genetic diversity
C) choose which organisms reproduce
D) perform artificial insemination
C) choose which organisms reproduce
29) Currently, two extant elephant species (X and Y) are classified in the genus Loxodonta, and a third species (Z) is placed in the genus Elephas. Thus, which statement should be true?
A) Species X and Y are not related to species Z.
B) Species X and Y share a greater number of homologies with each other than either does with species Z.
C) Species X and Y share a common ancestor that is alive today.
D) Species X and Y are the result of artificial selection.
B) Species X and Y share a greater number of homologies with each other than either does with species Z.
30) In a hypothetical environment, fishes called pike-cichlids are visual predators of large, adult algae-eating fish (in other words, they locate their prey by sight). The population of algae-eaters experiences predatory pressure from pike-cichlids. Which of the following is least likely to result in the algae-eater population in future generations?
A) selection for drab coloration of the algae-eaters
B) selection for nocturnal algae-eaters (active only at night)
C) selection for larger female algae-eaters, bearing broods composed of more, and larger, young
D) selection for algae-eaters that become sexually mature at smaller overall body sizes
C) selection for larger female algae-eaters, bearing broods composed of more, and larger, young
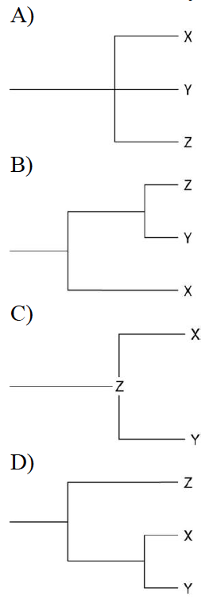
31) Currently, two of the living elephant species (X and Y) are placed in the genus Loxodonta and a third surviving species (Z) is placed in the genus Elephas. Assuming this classification reflects evolutionary relatedness, which of the following is the most accurate phylogenetic tree?
32) Cotton-topped tamarins are small primates with tufts of long white hair on their heads. While studying these creatures, you notice that males with longer hair get more opportunities to mate and father more offspring. To test the hypothesis that having longer hair is adaptive in these males, you should _____.
A) test whether other traits in these males are also adaptive
B) look for evidence of hair in ancestors of tamarins
C) determine if hair length is heritable
D) test whether males with shaved heads are still able to mate
C) determine if hair length is heritable
33) Fossils of Thrinaxodon, a species that lived during the Triassic period, have been found in both South Africa and Antarctica. Thrinaxodon had a reptile-like skeleton and laid eggs, but small depressions on the front of its skull suggest it had whiskers and, therefore, fur. Thrinaxodon may have been warm-blooded. The fossils of Thrinaxodon are consistent with the hypothesis that _____.
A) fossils found in a given area look like the modern species in that same area
B) the environment where it lived was very warm
C) mammals evolved from a reptilian ancestor
D) Antarctica and South Africa separated after Thrinaxodon went extinct
C) mammals evolved from a reptilian ancestor
34) Many crustaceans (for example, lobsters, shrimp, and crayfish) use their tails to swim, but crabs have reduced tails that curl under their shells and are not used in swimming. This is an example of _____.
A) convergent evolution
B) a homologous structure
C) natural selection
D) a vestigial trait
D) a vestigial trait
35) Which of the following, if discovered, could refute our current understanding of the pattern of evolution?
A) no fossils of soft-bodied animals
B) a modern bird having reptile-like scales on its legs
C) radioactive dating of rocks showing that rocks closer to the Earth's surface are younger than lower rock strata
D) diverse fossils of mammals in Precambrian rock
D) diverse fossils of mammals in Precambrian rock
36) Researchers discovered that a new strain of bacteria that cause tuberculosis (M. tuberculosis) taken from a dead patient has a point mutation in the rpoB gene that codes for part of the RNA polymerase enzyme. This mutant form of RNA polymerase does not function as well as the more common form of RNA polymerase. A commonly used antibiotic called rifampin does not affect the mutant rpoB bacteria.
A researcher mixes M. tuberculosis with and without the rpoB mutation and adds the bacteria to cell cultures. Half the cell cultures contain only standard nutrients, while the other half of the cell cultures contain rifampin and the standard nutrients. After many cell generations, the researcher finds that _____.
A) very few M. tuberculosis in the standard nutrient cell cultures carry the rpoB gene mutation, but almost all of the M. tuberculosis in the cell cultures with rifampin carry the rpoB mutation
B) almost all M. tuberculosis in the standard nutrient cell cultures carry the rpoB gene mutation, but very few of the M. tuberculosis in the cell cultures with rifampin carry the rpoB mutation
C) very few M. tuberculosis in any of the cell cultures carry the rpoB gene mutation
D) almost all of the M. tuberculosis in both types of cell cultures carry the rpoB mutation
A researcher mixes M. tuberculosis with and without the rpoB mutation and adds the bacteria to cell cultures. Half the cell cultures contain only standard nutrients, while the other half of the cell cultures contain rifampin and the standard nutrients. After many cell generations, the researcher finds that _____.
37) Scientific theories _____.
A) are nearly the same things as hypotheses
B) are supported by, and make sense of, many observations
C) cannot be tested because the described events occurred only once
D) are predictions of future events
B) are supported by, and make sense of, many observations
38) DDT was once considered a "silver bullet" that would permanently eradicate insect pests. Instead, DDT is largely useless against many insects. Which of these would have prevented this evolution of DDT resistance in insect pests?
A) All habitats should have received applications of DDT at about the same time.
B) The frequency of DDT application should have been higher.
C) None of the insect pests would have genetic variations that resulted in DDT resistance.
D) DDT application should have been continual.
C) None of the insect pests would have genetic variations that resulted in DDT resistance.
39) If the bacterium Staphylococcus aureus experiences a cost for maintaining one or more antibiotic-resistance genes, what would happen in environments that lack antibiotics?
A) These genes would be maintained in case the antibiotics appear.
B) These bacteria would be outcompeted and replaced by bacteria that have lost these genes.
C) These bacteria would try to make the cost worthwhile by locating and migrating to microenvironments where traces of antibiotics are present.
D) The number of genes conveying antibiotic resistance would increase in these bacteria.
B) These bacteria would be outcompeted and replaced by bacteria that have lost these genes.
40) Of the following anatomical structures, which is homologous to the bones in the wing of a bird?
A) bones in the hind limb of a kangaroo
B) chitinous struts in the wing of a butterfly
C) bony rays in the tail fin of a flying fish
D) bones in the flipper of a whale
D) bones in the flipper of a whale
41) Structures as different as human arms, bat wings, and dolphin flippers contain many of the same bones, which develop from similar embryonic tissues. These structural similarities are an example of _____.
A) homology
B) convergent evolution
C) the evolution of common structure as a result of common function
D) the evolution of similar appearance as a result of common function
A) homology
42) Over long periods of time, many cave-dwelling organisms have lost their eyes. Tapeworms have lost their digestive systems. Whales have lost their hind limbs. How can natural selection account for these losses?
A) Natural selection cannot account for losses, but accounts only for new structures and functions.
B) Natural selection accounts for these losses by the principle of use and disuse.
C) Under particular circumstances that persisted for long periods, each of these structures presented greater costs than benefits.
D) The ancestors of these organisms experienced harmful mutations that forced them to lose these structures.
C) Under particular circumstances that persisted for long periods, each of these structures presented greater costs than benefits.
43) Which of the following evidence most strongly supports the common origin of all life on Earth? All organisms _____.
A) require energy
B) use essentially the same genetic code
C) reproduce
D) show heritable variation
B) use essentially the same genetic code
44) Members of two different species possess a similar-looking structure that they use in a similar way to perform about the same function. Which of the following would suggest that the relationship more likely represents homology instead of convergent evolution?
A) The two species live at great distance from each other.
B) The two species share many proteins in common, and the nucleotide sequences that code for these proteins are almost identical.
C) The structures in adult members of both species are similar in size.
D) Both species are well adapted to their particular environments.
B) The two species share many proteins in common, and the nucleotide sequences that code for these proteins are almost identical.
45) What must be true of any organ described as vestigial?
A) It must be analogous to some feature in an ancestor.
B) It must be homologous to some feature in an ancestor.
C) It must be both homologous and analogous to some feature in an ancestor.
D) It need be neither homologous nor analogous to some feature in an ancestor.
B) It must be homologous to some feature in an ancestor.
46) Pseudogenes are _____.
A) composed of RNA, rather than DNA
B) the same things as introns
C) unrelated genes that code for the same gene product
D) nonfunctional vestigial genes
D) nonfunctional vestigial genes
47) It has been observed that organisms on islands are different from, but closely related to, similar forms found on the nearest continent. This is taken as evidence that ____.
A) island forms are descended from mainland forms
B) common environments are inhabited by the same organisms
C) island forms and mainland forms have identical gene pools
D) the island forms and mainland forms are converging
A) island forms are descended from mainland forms
48) Given what we know about evolutionary biology, we expect to find the largest number of endemic species in which of the following geological features, which have existed for at least a few million years?
A) an isolated ocean island in the tropics
B) an extensive mountain range
C) a grassland in the center of a large continent, with extreme climatic conditions
D) a shallow estuary on a warm-water coast
A) an isolated ocean island in the tropics
49) The greatest number of endemic species is expected in environments that are _____.
A) easily reached and ecologically diverse
B) isolated and show little ecological diversity
C) isolated and ecologically diverse
D) easily reached and show little ecological diversity
B) isolated and show little ecological diversity
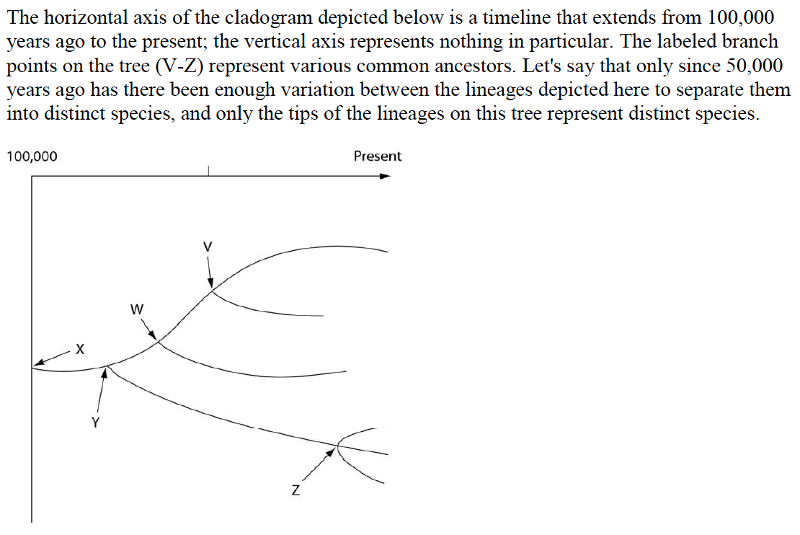
50) How many distinct species, both living and extinct, are depicted in this tree?
A) five
B) six
C) nine
D) eleven
D) eleven
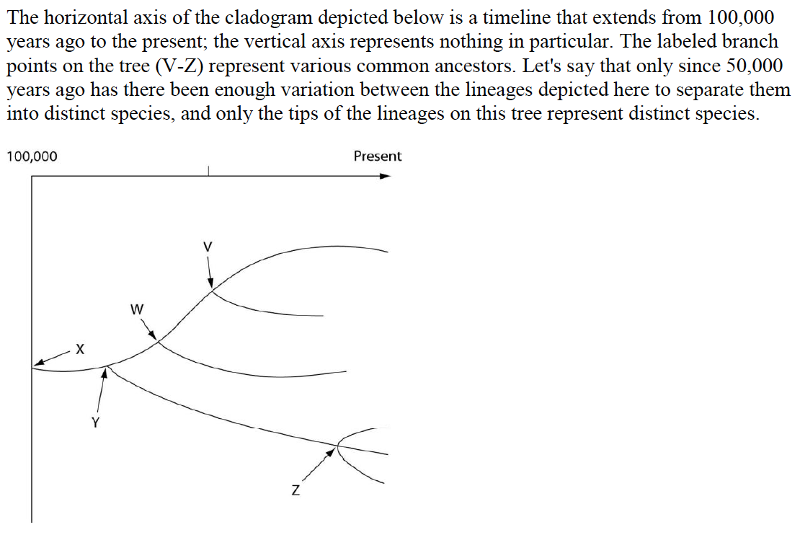
51) Which of the five common ancestors, labeled V-Z, is the common ancestor of the greatest number of species, both living and extinct?
A) V
B) W
C) Y
D) Z
C) Y
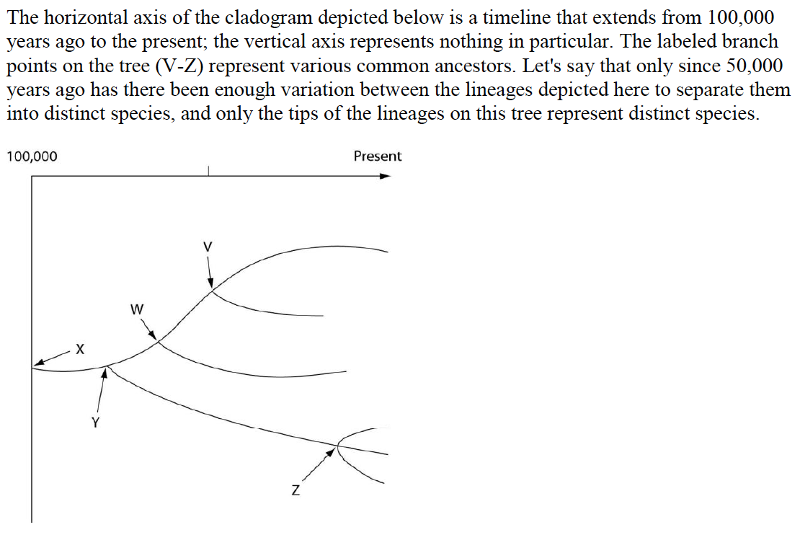
52) Which of the five species, labeled V-Z, is the common ancestor of the fewest number of species?
A) V
B) W
C) Y
D) Z
A) V
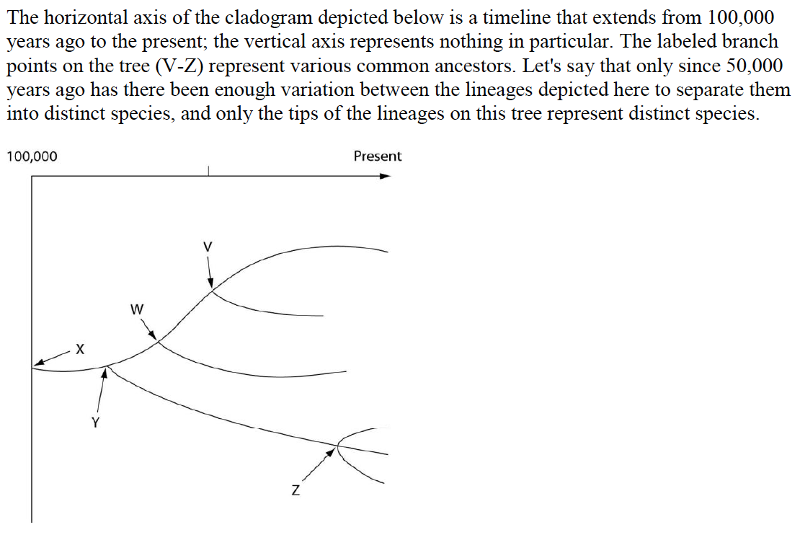
53) Evolutionary trees such as this are properly understood by scientists to be _____.
A) theories
B) hypotheses
C) dogmas
D) facts
B) hypotheses
54) About thirteen different species of finches inhabit the Galápagos Islands today, all descendants of a common ancestor from the South American mainland that arrived a few million years ago. Genetically, there are four distinct lineages, but the thirteen species are currently classified among three genera. The first lineage to diverge from the ancestral lineage was the warbler finch (genus Certhidea). Next to diverge was the vegetarian finch (genus Camarhynchus), followed by five tree finch species (also in genus Camarhynchus) and six ground finch species (genus Geospiza). If the six ground finch species have evolved most recently, then which of these is the most logical prediction?
A) They should be limited to the six islands that most recently emerged from the sea.
B) Their genomes should be more similar to each other than are the genomes of the five tree finch species.
C) They should share fewer anatomical homologies with each other than they share with the tree finches.
D) The chances of hybridization between two ground finch species should be less than the chances of hybridization between two tree finch species.
B) Their genomes should be more similar to each other than are the genomes of the five tree finch species.
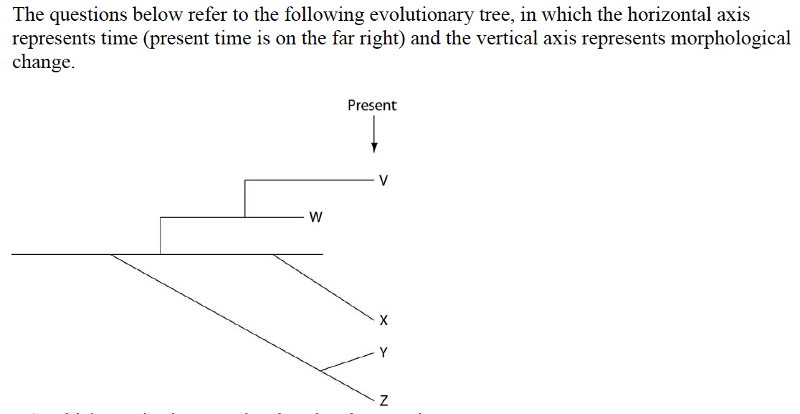
55) Which species is most closely related to species W?
A) V is most closely related to species W.
B) X is most closely related to species W.
C) Y and Z are equally closely related to W.
D) It is not possible to say from this tree.
A) V is most closely related to species W.
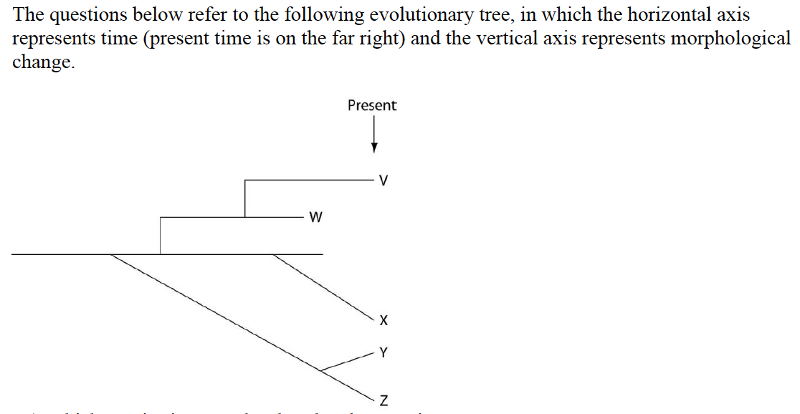
56) Which of these is the extant (that is, living) species most closely related to species X?
A) V
B) W
C) Y
D) Z
A) V
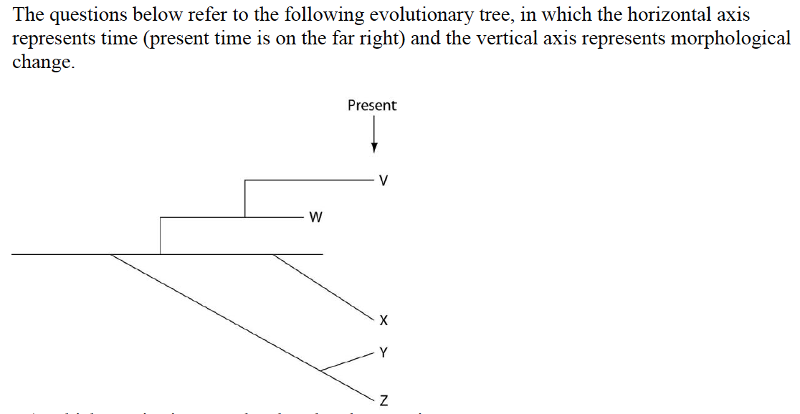
57) Logically, which of these should cast the most doubt on the relationships depicted by an evolutionary tree?
A) Some of the organisms depicted by the tree had lived in different habitats.
B) The skeletal remains of the organisms depicted by the tree were incomplete (in other words, some bones were missing).
C) Transitional fossils had not been found.
D) Relationships between DNA sequences among the species did not match relationships between skeletal patterns.
D) Relationships between DNA sequences among the species did not match relationships between skeletal patterns.